Can AI Read Like a Financial Analyst? A New Study Puts Top LLMs to the Test
A New Frontier for AI in Finance: Reading Annual Reports
For financial analysts, wading through hundreds of pages of dense annual reports is a fundamental, time-consuming part of the job. Investors read these reports directly, or read secondary equity research written by financial analysts [2]. These documents, which can exceed 700 pages, are packed with financial data, regulatory disclosures, and strategic narratives that drive investment decisions. The complexity is immense; analysts must connect hundreds of financial metrics, temporal data, and subtle narrative cues to form a coherent investment thesis and use the reports to set stock price targets [5, 11] and give investment recommendations [4, 27].
This critical task seems ripe for AI automation, but a key question has remained: can AI systems truly comprehend these documents with the reliability required for high-stakes financial decisions? Our new paper, “Can AI Read Like a Financial Analyst?”, tackles this question head-on by conducting the most comprehensive open evaluation of leading AI models on financial document comprehension.
Putting AI to the Test with Financial Touchstone
To create a fair and unbiased evaluation, we first had to address a major concern in AI research: training data contamination. We needed to ensure the models we tested had never seen our evaluation questions before.
To do this, we introduced Financial Touchstone, a new large-scale benchmark guaranteed to be unseen by the models. It’s one of the largest and most diverse datasets of its kind:
- 480 international annual reports from 22 countries, ensuring a global scope beyond just the US.
- 2,878 question-context-answer triplets, focusing on the types of questions professional analysts ask most frequently [25].
- Over 83 million tokens of high-quality financial text, primarily from the years 2021-2023.
Using this benchmark, we tested eleven of the world’s most advanced language models, including Google’s Gemini 2.5 Pro, OpenAI’s o3, Anthropic’s Claude 4 Opus, and xAI’s Grok 4. To handle the immense length of the documents, we used a standard Retrieval-Augmented Generation (RAG) architecture [15], which first finds relevant passages and then feeds them to the model to generate an answer.
The Surprising Bottleneck: It’s Not Reasoning, It’s Retrieval
Our findings fundamentally reframe the challenge of automating financial analysis. The results show that the top “reasoning” models are remarkably capable of understanding complex financial text when given the correct information.
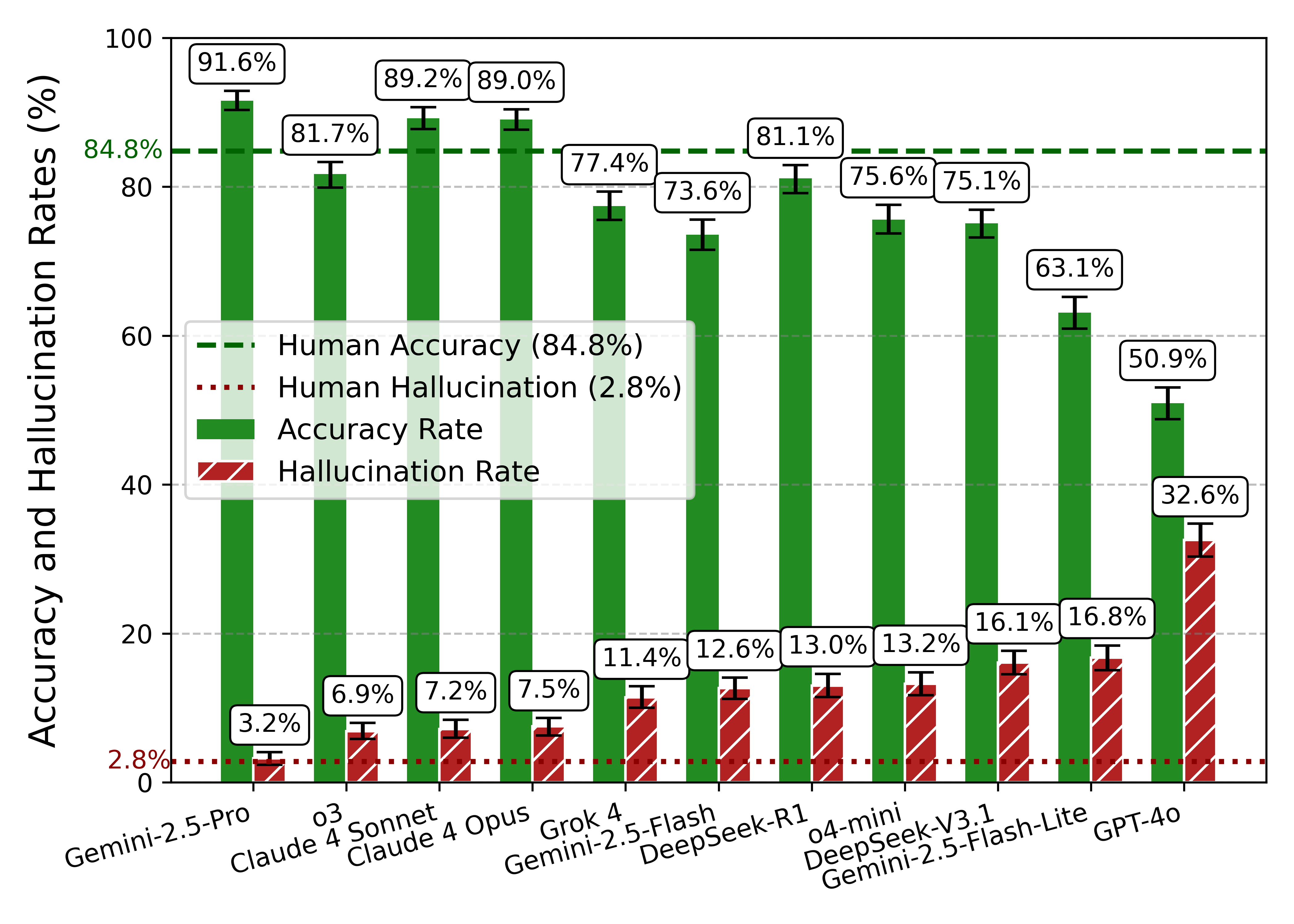
Google’s Gemini 2.5 Pro led the pack, achieving an impressive 91.6% accuracy with a hallucination rate of just 3.2%. This performance actually surpasses the human baseline for accuracy (84.8%) we established in our study, though humans still make fewer unfounded claims (2.8% hallucination rate). Models like OpenAI’s o3 and Anthropic’s Claude 4 models also performed exceptionally well.
However, this high accuracy comes with a huge caveat. The primary bottleneck is not the model’s comprehension ability, but the initial information retrieval step.
When the RAG system failed to find and provide the correct context from the annual report, model accuracy plummeted to a staggering 0.2%.
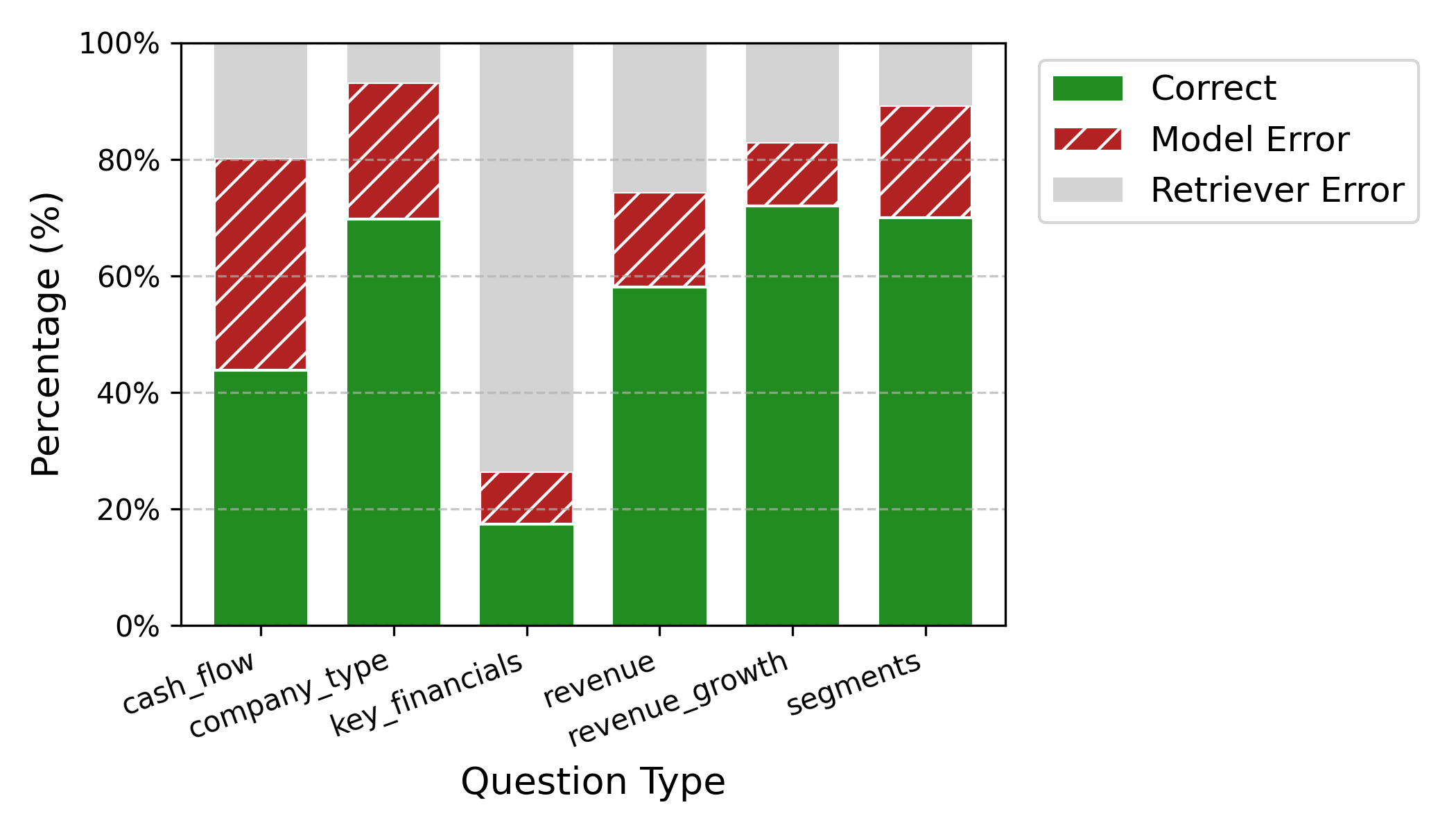
Our failure analysis revealed that a shocking two-thirds (66.5%) of all errors stemmed from the retriever failing to find the “needle in the haystack” [21]. In contrast, true model comprehension errors accounted for only 3% of failures. This demonstrates that future progress hinges more on solving the challenge of targeted information retrieval than on incremental improvements in model reasoning alone.
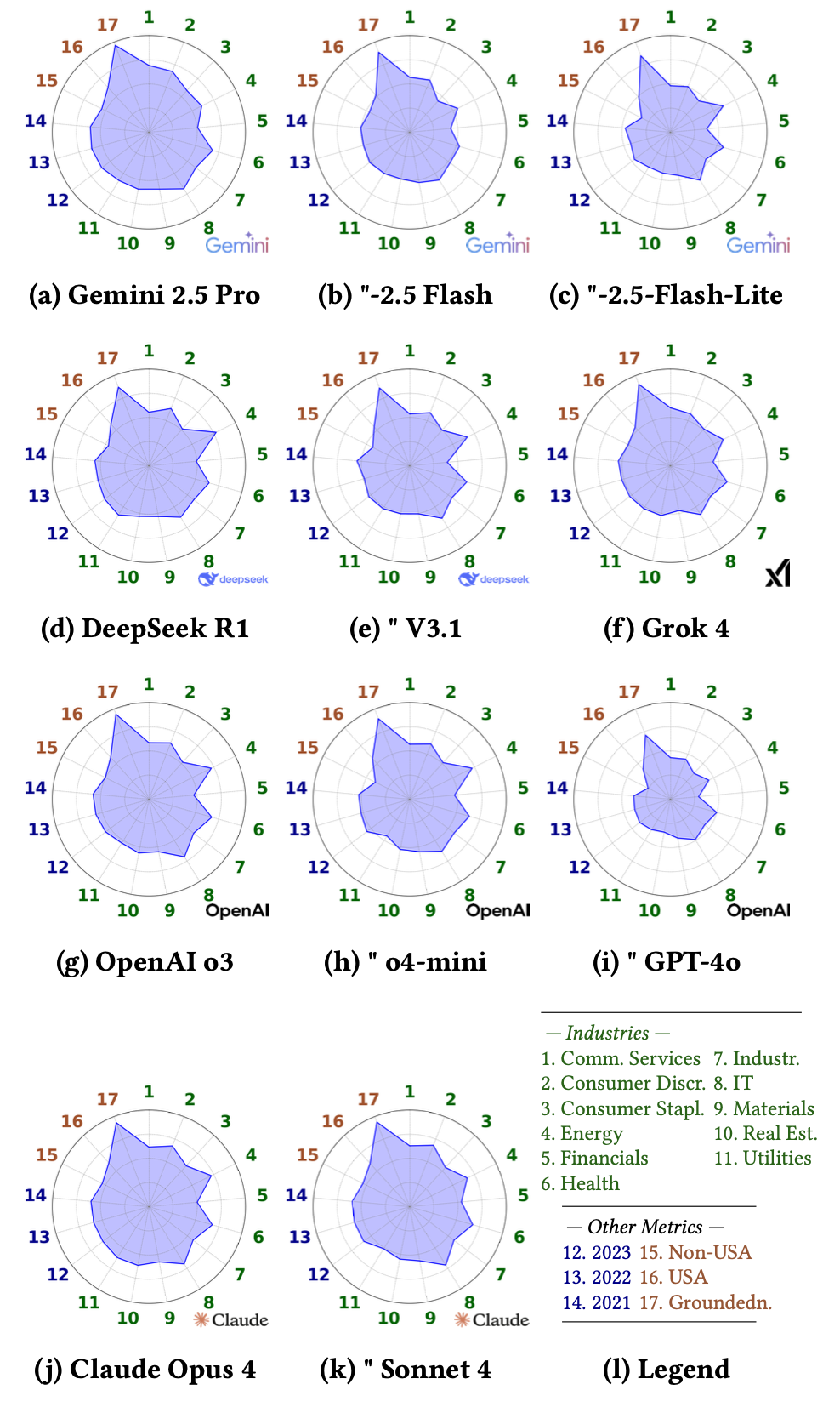
As we have already seen in our prior research [25], models often have low error overlap, offering promising potential for LLM ensembles. LLMs can thus correct each other in some cases. This further strengthens the generative part of RAG pipelines, while making the need for better retrieval even more pressing.
Key Insights and Future Directions
Our study provides a clear roadmap for the future of AI in financial analysis.
- Retrieval is the new frontier. The central challenge isn't asking "Can AI read?" but rather, "Can AI find what it needs to read?". Building better retrievers—perhaps using advanced methods like GraphRAG [12]—is the most critical next step.
- Reasoning models are essential. There is a significant performance gap between "reasoning" and "non-reasoning" models. The top models deliver a 15+ percentage point uplift in accuracy and are far better at avoiding hallucinations, making them a prerequisite for reliable financial tools.
- Model ensembling shows promise. We found very low agreement between the different top models. This suggests that production systems could achieve higher reliability by combining the outputs of several diverse models, such as an ensemble of Gemini 2.5 Pro, OpenAI's o3, and Anthropic's Claude Sonnet 4.
Conclusion
So, can AI read like a financial analyst? Our research provides a qualified “yes”—but only if it’s given the right pages. The reasoning capabilities of today’s frontier models are largely sufficient for the task.
The evidence is clear: the most direct path to unlocking the next generation of AI in finance is to solve the fundamental challenge of information retrieval. With the accuracy and reliability demonstrated by the top models, AI is poised to enhance trust and transparency in equity research, helping to address long-standing issues of analyst bias and conflicts of interest [20].
To accelerate this effort, we are making the complete Financial Touchstone dataset, evaluation framework, and source code publicly available upon publication.
Link to the Paper
References
[2] Asquith, P., Mikhail, M., & Au, A. (2005). Information Content of Equity Analyst Reports. Journal of Financial Economics, 75(2), 245-282.
[4] Barber, B., Lehavy, R., McNichols, M., & Trueman, B. (2001). Can Investors Profit From the Prophets? Security Analyst Recommendations and Stock Returns. The Journal of Finance, 56(2), 531-563.
[5] Bonini, S., Zanetti, L., Bianchini, R., & Salvi, A. (2010). Target Price Accuracy in Equity Research. Journal of Business Finance & Accounting, 37(9-10), 1177-1217.
[11] Gleason, C., Johnson, B., & Li, H. (2013). Valuation Model Use and the Price Target Performance of Sell-Side Equity Analysts. Contemporary Accounting Research, 30(1), 80-115.
[12] Han, H., Shomer, H., Wang, Y., Lei, Y., Guo, K., Hua, Z., Long, B., Liu, H., & Tang, J. (2025). RAG vs. GraphRAG: A Systematic Evaluation and Key Insights. arXiv.
[15] Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-T., Rocktäschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NIPS), 33, 9459-9474.
[20] Michaely, R., & Womack, K. (1999). Conflict of Interest and the Credibility of Underwriter Analyst Recommendations. The Review of Financial Studies, 12(4), 653-686.
[21] Nelson, E., Kollias, G., Das, P., Chaudhury, S., & Dan, S. (2024). Needle in the Haystack for Memory Based Large Language Models. ICML 2024 Workshop-Next Generation of Sequence Modeling Architectures.
[25] Pop, A., & Spörer, J. (2025). Identification of the Most Frequently Asked Questions in Financial Analyst Reports to Automate Equity Research Using Llama 3 and GPT-4. IEEE Swiss Data Science Conference (SDS).
[27] Womack, K. (1996). Do Brokerage Analysts’ Recommendations Have Investment Value? The Journal of Finance, 51(1), 137-167.