LLM Benchmark Evaluation - Apertus-8B
The Release
On September 2, 2025, the Swiss AI Initiative — a collaboration between ETH Zurich, EPFL, and the Swiss National Supercomputing Centre (CSCS) — released the Apertus model family in two sizes: 8B and 70B parameters.
The larger variant, Apertus-70B, is the first fully open model trained at this scale, developed on 4,096 GPUs using 15 trillion tokens.
The models are:
- Trained solely on publicly available data
- Respectful of robots.txt exclusions (retroactively)
- Filtered for copyrighted, non-permissive, toxic, and personally identifiable content
- Equipped with the Goldfish loss to limit verbatim memorization
Apertus supports 1,811 languages, including Swiss regional languages such as Romansh and Schwiizerdütsch. The release includes both the model weights and full reproduction artifacts for the research community.
Benchmarking the Model
We took the opportunity to benchmark the model against other models using several industry-standard benchmarks.
The technical report[1] already contains comparisons with common open weight and open source models. Our goal was to:
- Get our own impressions of Apertus
- Evaluate whether we could reproduce the benchmarks presented in the report
At this point, we highly recommend everyone take a look at the technical report for the Apertus models. It is relatively rare to find such detailed insights into state-of-the-art LLM trainings.
Open Weight vs. Open Models
In this article, we follow the terminology used by the editors of the Technical Report and draw a clear distinction:
Open Weight Models
- Weights and architectures are openly available
- Training data, scripts, and reproducibility artifacts are not published
- Example: Llama model family from Meta
Open Models
- Strive to make everything open: data, scripts, training details
- Aim for reproducibility and knowledge sharing in a scientific context
- Example: OLMO model family from the Allen Institute for AI
Why Open Models Matter
Although open models often lag behind open weight and closed models (e.g., GPT-5 from OpenAI, or Gemini) in performance, they provide:
- Training on ethical datasets
- Development on a non-profit basis
- Opportunities for open research that is not profit-driven
Despite their current limitations in quality compared to top-tier chat applications, open models are extremely important for society. They advance the entire field of LLM Foundation Training research through transparency, reproducibility, and community-driven progress.
Quicklinks to Alpertus Ressources:
- Technical Report: Swiss-AI Apertus Technical Report
- Model Hub: Hugging Face - Swiss AI Models
- Official Blog: Swiss AI Apertus Announcement
Important disclaimer: The benchmarks were created using the Apertus-8B-Instruct from Hugging Face with a subset of the leaderboard evaluations from ElutherAI’s Language Model Evaluation Harness. The raw results and benchmark logs can be found on our Github repository unisg-ics-dsnlp/Apertus8B-Instruct-Benchmark-Results.
The benchmarks presented here are not intended to be exhaustive and are intended only to provide an overview and initial, independent assessment of the model. For more comprehensive benchmarks, please refer to the Swiss-AI Apertus Technical Report.
Selected Benchmarks
We evaluated the model across four key benchmarks that test different aspects of language understanding and generation capabilities:
1. IFEval (Instruction Following Evaluation)
- Task Type: 0-shot, generative
- Purpose: Measures the model’s ability to follow specific, verifiable instructions
- Examples: Tasks involving word count constraints, keyword usage, formatting requirements
- Why it matters: Instruction-following is crucial for practical applications where models must adhere to specific user requirements
2. MATH-lvl-5 (Mathematical Reasoning)
- Task Type: 4-shot, generative
- Purpose: Tests mathematical problem-solving capabilities using challenging level-5 problems
- Examples: Complex algebraic equations, calculus problems, geometric reasoning
- Why it matters: Mathematical reasoning demonstrates logical thinking and step-by-step problem decomposition skills
3. MMLU-Pro (Enhanced Multi-task Language Understanding)
- Task Type: 5-shot, multiple-choice
- Purpose: Comprehensive evaluation across diverse academic and professional domains
- Examples: Science, history, law, medicine, engineering questions with 10 answer choices
- Why it matters: Broad domain knowledge is essential for general-purpose language models
4. Musr (Multi-step Soft Reasoning)
- Task Type: 0-shot, multiple-choice
-
Purpose: Evaluates complex narrative reasoning across three sub-tasks:
- Murder Mysteries: Logical deduction from narrative clues
- Object Placements: Spatial and temporal reasoning
- Team Allocation: Constraint satisfaction and optimization
- Why it matters: Tests the model’s ability to maintain context and reason through multi-step scenarios
We might add more benchmarks in the future.
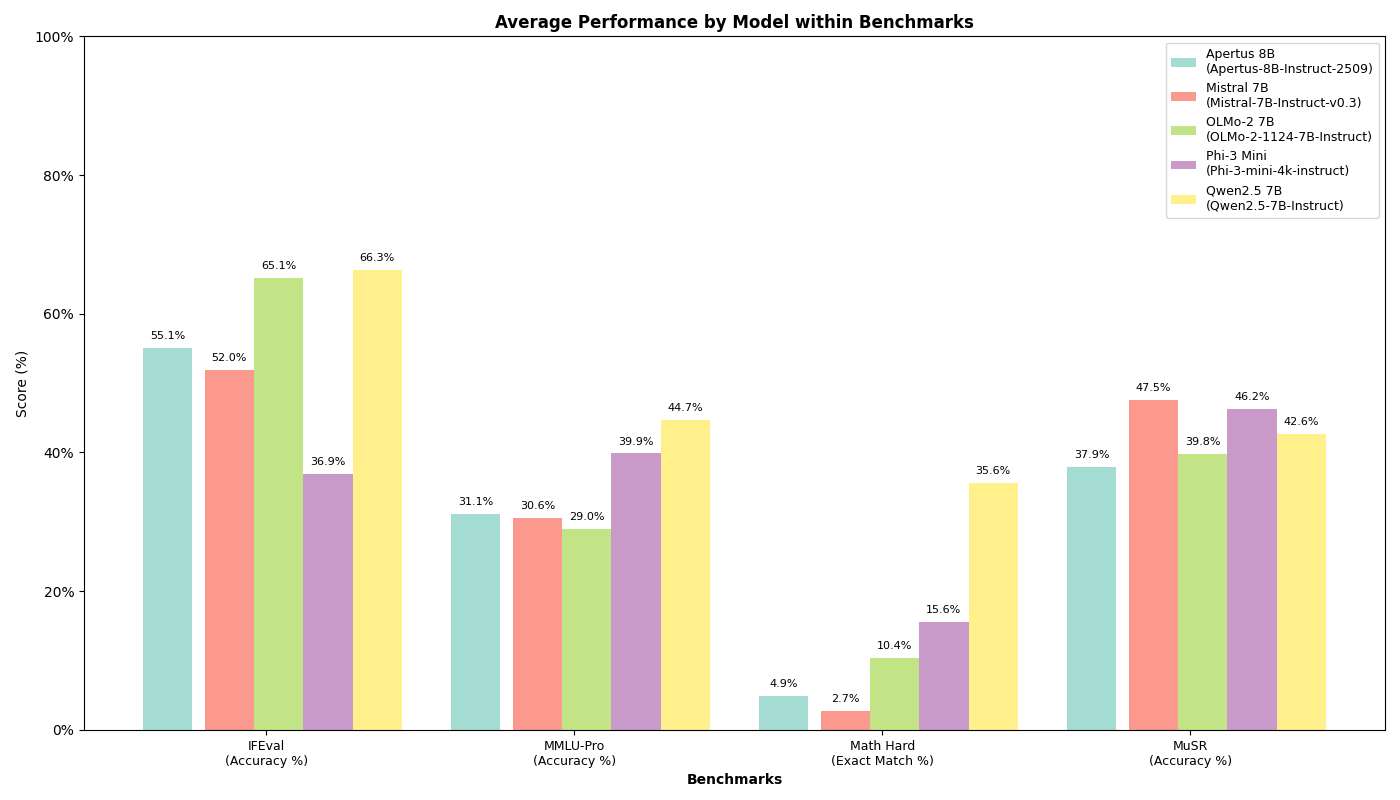
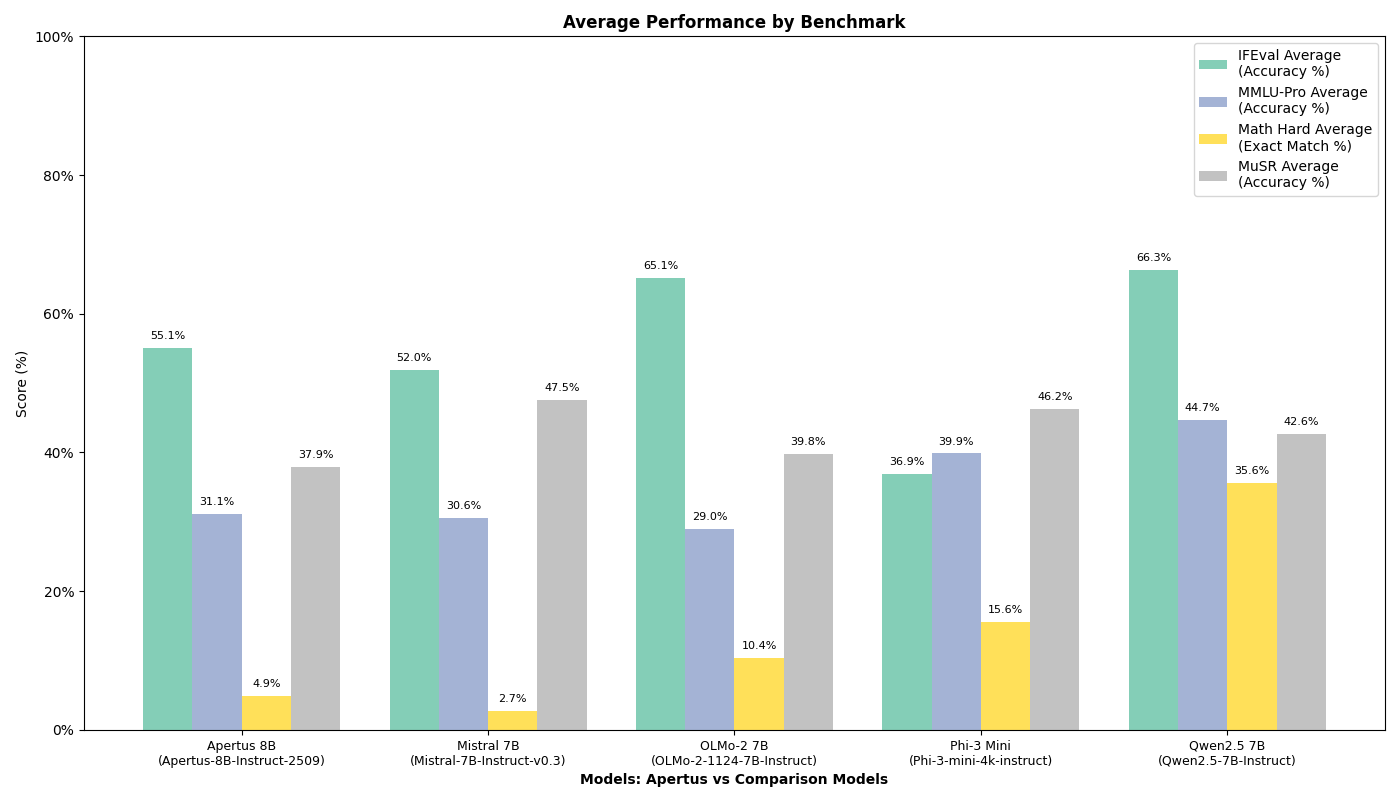
Benchmark Results
Most of the Math-lvl-5 and MMLU-Pro benchmark results are still missing and will be updated gradually.
Performance Comparison
The following table presents our benchmark results for Apertus-8B-Instruct compared to other open-weight and open models in similar parameter ranges:
| Model | IFEval (0-shot) [3] | MMLU-Pro (5-shot) [5] | Math-lvl-5 (4-shot) [6] | Musr (0-shot) [4] |
|---|---|---|---|---|
| Apertus 8B Instruct 2509 | 44.18% | 31.14% | 5.29% | 36.00% |
| OLMo-2 1124 7B Instruct | 57.67% | 29.02% | 11.71% | 39.81% |
| Mistral 7B Instruct v0.3 | 44.73% | 30.56% | 2.95% | 44.33% |
| Phi-3 Mini 4k Instruct | 29.39% | 39.85% | 16.99% | 44.00% |
| Qwen2.5 7B Instruct | 58.04% | 44.72% | 37.08% | 42.59% |
Note: Values represent accuracy scores. Dashes (-) indicate pending or unavailable results.
Detailed IFEval Performance Breakdown
The IFEval benchmark measures different aspects of instruction following capability. Here’s the detailed breakdown across all evaluated metrics:
| Model | Inst Level Loose | Inst Level Strict | Prompt Level Loose | Prompt Level Strict |
|---|---|---|---|---|
| Apertus 8B Instruct 2509 | 65.35% | 57.55% | 53.23% | 44.18% |
| OLMo-2 1124 7B Instruct | 72.42% | 67.51% | 62.85% | 57.67% |
| Mistral 7B Instruct v0.3 | 59.59% | 56.35% | 47.13% | 44.73% |
| Phi-3 Mini 4k Instruct 4k | 44.36% | 43.41% | 30.50% | 29.39% |
| Qwen2.5 7B Instruct | 73.98% | 68.82% | 64.51% | 58.04% |
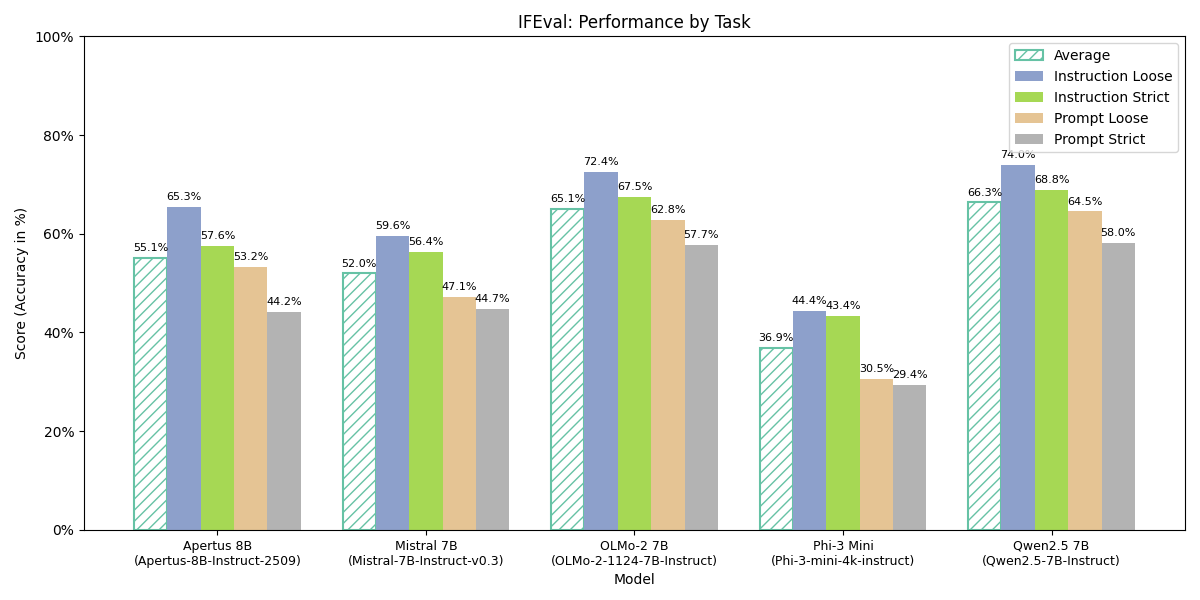
Understanding IFEval Metrics:
-
Instruction Level: Evaluates individual instruction compliance within a prompt
- Loose: More lenient evaluation allowing minor deviations
- Strict: Rigorous evaluation requiring exact compliance
-
Prompt Level: Evaluates overall prompt-level instruction following
- Loose: Partial credit for partially followed instructions
- Strict: All-or-nothing evaluation requiring complete instruction compliance
Paper: Zhou et al. 2023: Instruction-Following Evaluation for Large Language Models
Detailed Math Hard
| Model | Overall | Algebra | Counting & Prob | Geometry | Intermediate Algebra | Number Theory | Prealgebra | Precalculus |
|---|---|---|---|---|---|---|---|---|
| Apertus 8B Instruct 2509 | 5.29% | 7.82% | 3.25% | 3.03% | 1.43% | 4.55% | 13.47% | 0.74% |
| OLMo-2 1124 7B Instruct | 11.71% | 25.41% | 8.94% | 6.82% | 1.43% | 5.84% | 21.76% | 1.48% |
| Mistral 7B Instruct v0.3 | 2.95% | 4.89% | 1.63% | 0.00% | 0.71% | 1.30% | 7.77% | 2.22% |
| Phi-3 Mini 4k Instruct | 16.99% | 30.94% | 12.20% | 6.82% | 2.86% | 14.94% | 36.27% | 3.70% |
| Qwen2.5 7B Instruct | 37.08% | 61.89% | 39.84% | 26.52% | 13.21% | 37.01% | 51.81% | 17.04% |
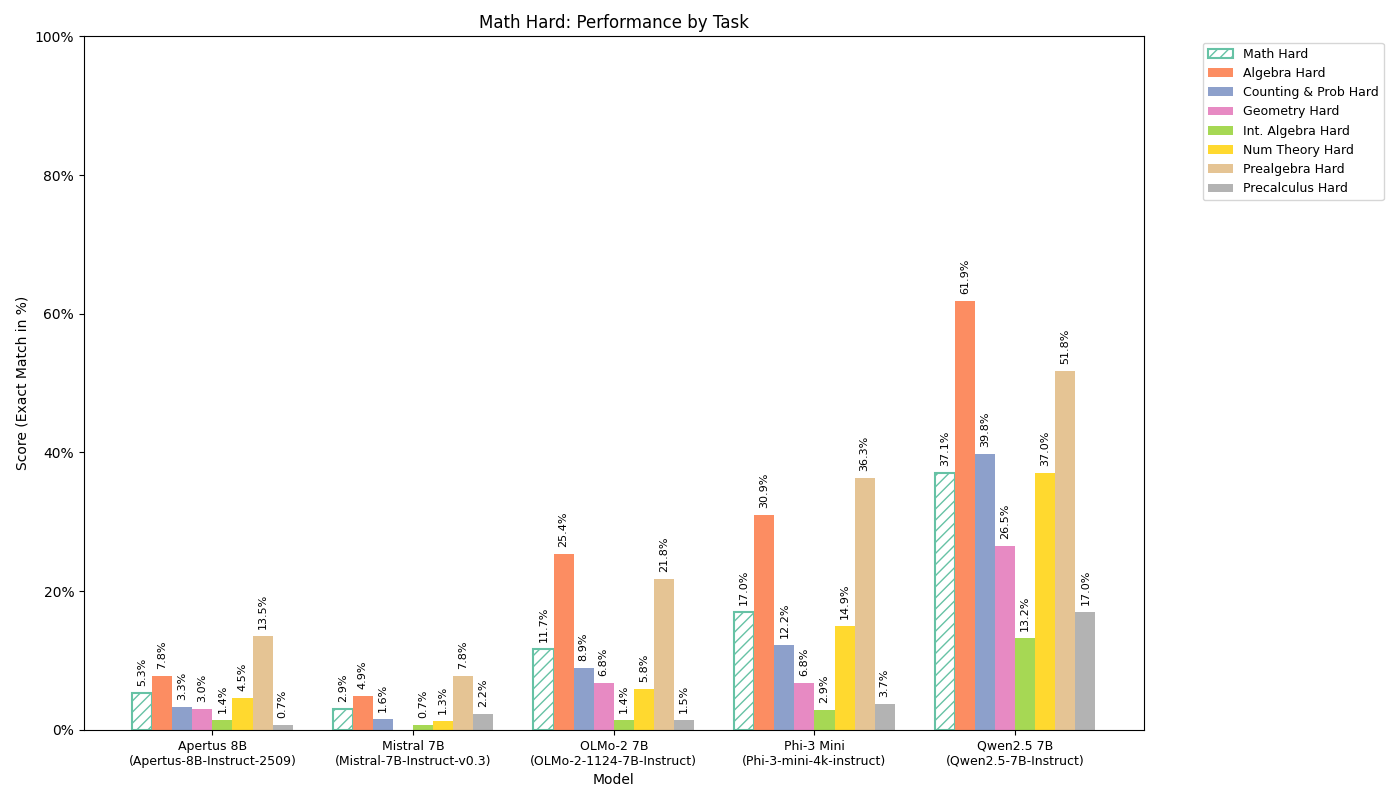
Paper: Hendrycks et al. 2021: Measuring Mathematical Problem Solving With the MATH Dataset
Detailed Musr Sub-task Performance
| Model | Murder Mysteries | Object Placements | Team Allocation | Overall |
|---|---|---|---|---|
| Apertus 8B Instruct 2509 | 56.00% | 24.00% | 28.00% | 36.00% |
| OLMo-2 1124 7B Instruct | 51.60% | 36.72% | 31.20% | 39.81% |
| Mistral 7B Instruct v0.3 | 49.00% | 34.00% | 50.00% | 44.33% |
| Phi-3 Mini 4k Instruct 4k | 59.00% | 35.00% | 38.00% | 44.00% |
| Qwen2.5 7B Instruct | 53.60% | 36.33% | 38.00% | 42.59% |
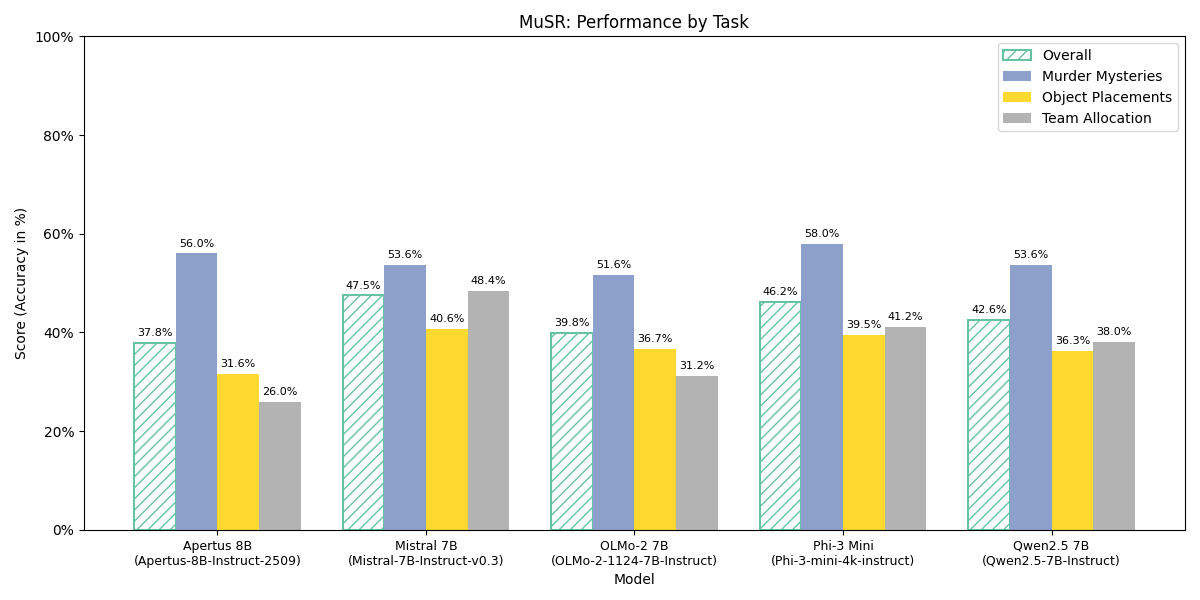
Paper: Sprague et al. 2024: MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning
Comparison with Official Benchmarks
To validate our results, we compared our IFEval benchmark results with those reported in the Apertus Technical Report:
| Model | Our IFEval Results | Tech Report IFEval Results | Difference |
|---|---|---|---|
| Apertus 8B Instruct 2509 | 53.23% | 71.7%* | -18.47 |
| OLMo-2-1124-7B-Instruct | 57.67% | 71.0%* | -13.33% |
*Tech Report: Post-training evaluation using prompt-level strict accuracy (Table 19)
Important Notes on IFEval Comparison:
The performance differences between our results and the Tech Report can be attributed to:
-
Evaluation Implementation Differences:
- Different prompt templates and formatting
- Variations in instruction parsing and evaluation criteria
- Potential differences in the lm-evaluation-harness versions (See github.com/swiss-ai/lm-evaluation-harness)
-
Consistency Across Models:
- Both Apertus-8B-Instruct and OLMo-2-7B-Instruct show lower scores in our evaluation
- The consistent gap suggests systematic differences in evaluation methodology
- This highlights the importance of using identical evaluation settings for fair comparisons
This may not necessarily mean that the results are directly comparable with the official benchmarks. However, this does not affect the comparability between the models in our benchmark.
Key Observations
- Instruction Following (IFEval): Apertus-8B-Instruct shows competitive performance at 44.18%, though it trails behind models like OLMo-2 (57.67%) and Qwen2.5 (58.04%)
- Mathematical Reasoning: With 5.29% on Math-lvl-5, Apertus-8B-Instruct outperforms Mistral 7B (2.95%).
- Multi-domain Knowledge (MMLU-Pro): Achieved 31.14% accuracy across 12,032 samples
- Multi-step Reasoning (Musr): Shows room for improvement with 36.00% overall, particularly in object placement tasks (24.00%)
References
[1] Swiss AI Initiative. (2025). Apertus Technical Report. GitHub Repository. https://github.com/swiss-ai/apertus-tech-report
[2] Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Le Noac’h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., & Zou, A. (2023). A framework for few-shot language model evaluation. Zenodo. https://doi.org/10.5281/zenodo.10256836
[3] Zhou, A., Yan, K., Shlapentokh-Rothman, M., Wang, H., & Wang, Y. (2023). Instruction-Following Evaluation for Large Language Models. arXiv preprint. https://arxiv.org/abs/2311.07911
[4] Sprague, C., Gao, L., Biderman, S., & Sutawika, L. (2024). MuSR: Testing the Limits of Chain-of-thought with Multistep Soft Reasoning. arXiv preprint. https://arxiv.org/abs/2310.16049
[5] Wang, Y., Ma, X., Zhang, G., Ni, Y., Chandra, A., Guo, S., Ren, W., Arulraj, A., He, X., Jiang, Z., Li, T., Ku, M., Wang, K., Zhuang, A., Fan, R., Yue, X., & Chen, W. (2024). MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark. arXiv preprint. https://arxiv.org/abs/2406.01574
[6] Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., & Steinhardt, J. (2021). Measuring Mathematical Problem Solving With the MATH Dataset. arXiv preprint. https://arxiv.org/abs/2103.03874
